R&D Initiative · Domain Partnership
Knowledge-Intensive Operations · Management Consulting
2026
Knowledge-intensive firms run on human judgment at every operational layer — interpreting client communications, tracking scope, producing deliverables, retaining institutional knowledge across engagements. Each layer depends on experienced people carrying context. Each layer is a bottleneck with a cost that doesn't appear cleanly on a P&L. The question wasn't whether AI could help. It was whether you could redesign the operation around it — not as a feature bolted on top, but as the architecture underneath.
A working product POC covering the full consulting lifecycle — autonomous email classification, real-time scope detection, AI-driven deliverable generation, persistent organisational memory, and agent-based task execution. The system keeps humans at the decision layer while AI handles interpretation and production. The architecture is the product.
Next Halo operates as a vertical AI studio. The model is deliberate: identify a domain where operational complexity is high, find the practitioner who has lived that problem longest, and co-own the problem definition before writing a line of code. Not as a client relationship. As a partnership — shared conviction that the problem is worth solving, shared stake in whether the solution is real.
For this initiative, that partner was a strategy consultant with 15+ years inside tier-one and boutique firms — partner-level, with direct exposure to the operational failures this system was built to address. They didn't hand us a brief. They challenged every assumption about how consulting operations actually break, which layers AI could own reliably, and what human judgment still couldn't be replaced. That collaboration shaped the architecture at the problem level, before any technical decisions were made. It is ongoing.
The starting point was not technology — it was understanding how a knowledge-intensive operation actually runs. A consulting firm was the test case: complex enough to stress every assumption, structured enough to map completely. The domain knowledge that made this possible didn't come from observation — it came from a practitioner who had run these engagements from the inside, for years, at senior level. Every engagement follows a recognisable pattern: an RFP arrives, a brief is drafted, deliverables are scoped, and then the real work begins — managing client communications, detecting scope changes before they become budget overruns, producing deliverables that meet the original intent, and carrying knowledge across engagements.
Each of these functions traditionally requires experienced human judgment at every step. The architectural question: which of these layers can AI handle reliably, and where must humans remain?
The answer shaped a two-tier system:
Key architectural decisions:
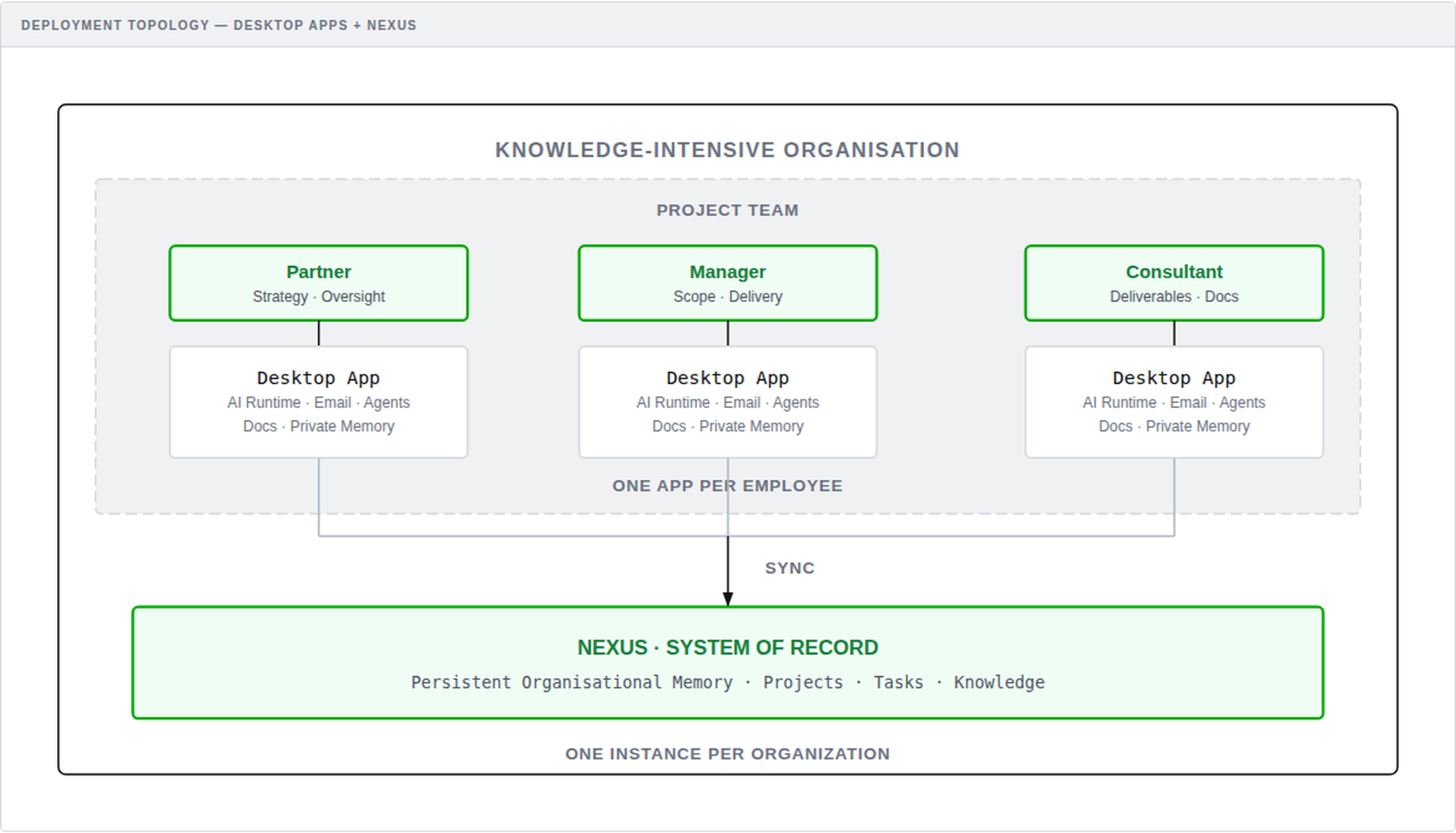
Deployment Topology: Each team member runs a local desktop app with AI runtime, syncing to a central Nexus system of record
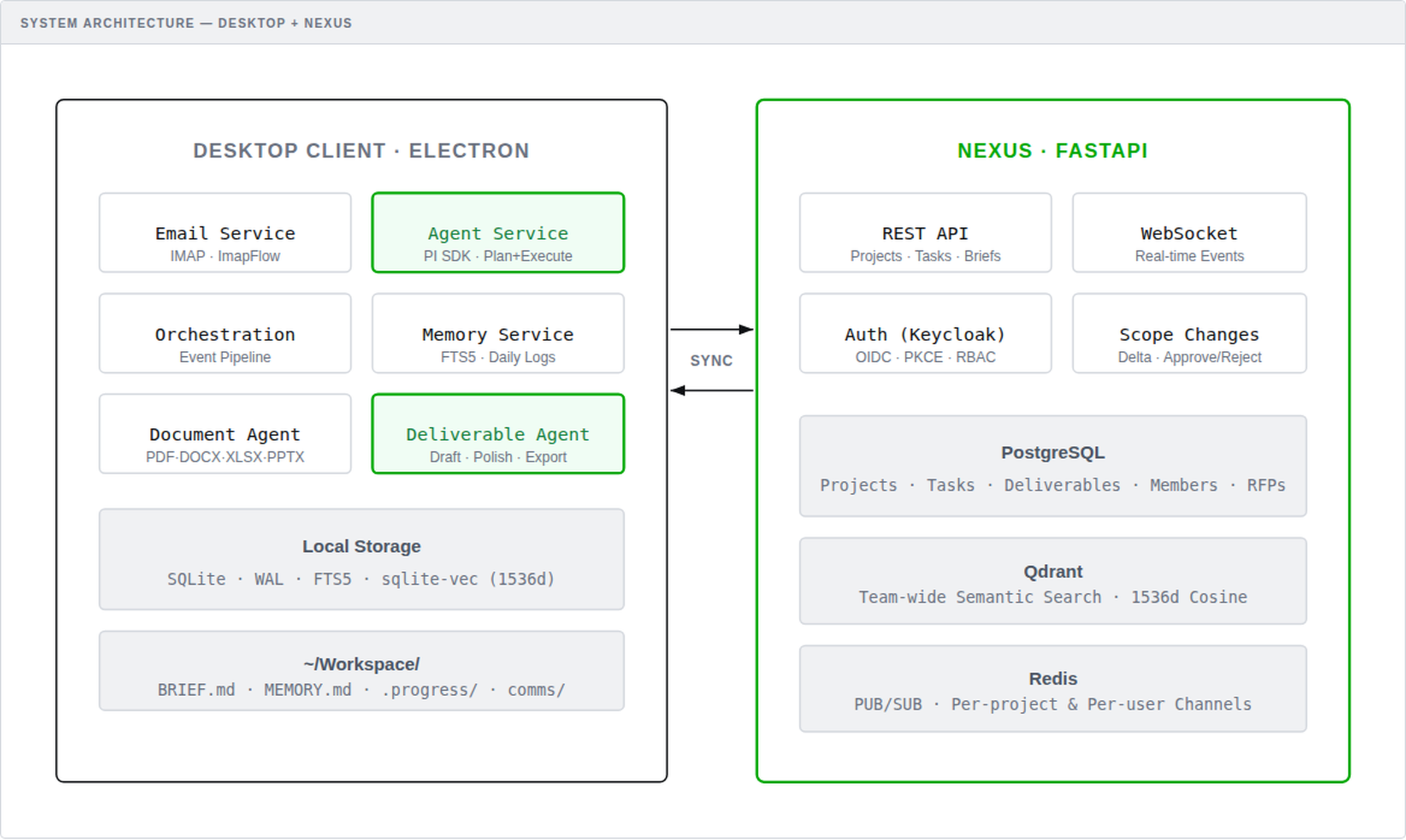
System Architecture: Electron desktop client with local services connected via sync to the FastAPI-based Nexus server
The platform's capability is delivered through five core systems, each addressing a critical workflow layer.
The system reads client emails with the same context an engagement manager would carry. Each classification runs against the project's full brief, RFP documents, deliverable structure, and communication history — not keyword matching on subject lines.
The classifier uses tool-based LLM classification. The model receives structured tools (match_and_push, suggest_new_project, skip_email) and is forced to choose one, returning structured JSON with project matching and explicit reasoning.
Scope detection operates on intent, not keywords. When a client email says “could we also include a competitor analysis in the final deck,” the system reasons about whether that deliverable exists in the current scope, whether it's implied by adjacent work, or whether it represents genuine scope expansion. Output is structured: in_scope, scope_creep, or uncertain — with a summary, affected tasks, and reasoning.
The design is conservative by default. False negatives are recoverable. False positives destroy trust. The system tunes for precision over recall — and the difference in user adoption is immediate.
The POC uses email and local files as its primary signal sources, but the event-driven architecture generalises to any communication channel — Slack, WhatsApp, Microsoft Teams, and similar. The classification and orchestration layers are channel-agnostic by design; adding a new input source means writing an adapter, not rearchitecting the pipeline.
The processing pipeline is fully autonomous from ingestion to Manager notification. An OrchestrationService coordinates specialised services in sequence: Email arrives → Classification → RFP Detector → Delta Extractor → Brief Updater → Manager Notification.
Each service has a single responsibility — microservices thinking applied to AI. The RFPDetector determines if a communication contains an RFP. The DeltaExtractor compares it against the existing brief and scope. The BriefService generates or appends updated content. The DeliverableAgentService handles section-level drafting and assembly.
Clear boundaries make each service independently testable, debuggable, and improvable. When classification accuracy dips, the problem is isolated to one service. When delta extraction needs refinement, one service changes — nothing else is touched.
The human checkpoint sits at the decision point — approve or reject a proposed scope change — not at every detection step. The system detects and prepares; the Manager decides and approves. Real-time coordination runs on Redis PUB/SUB with WebSocket connections for live updates on per-project and per-user channels.
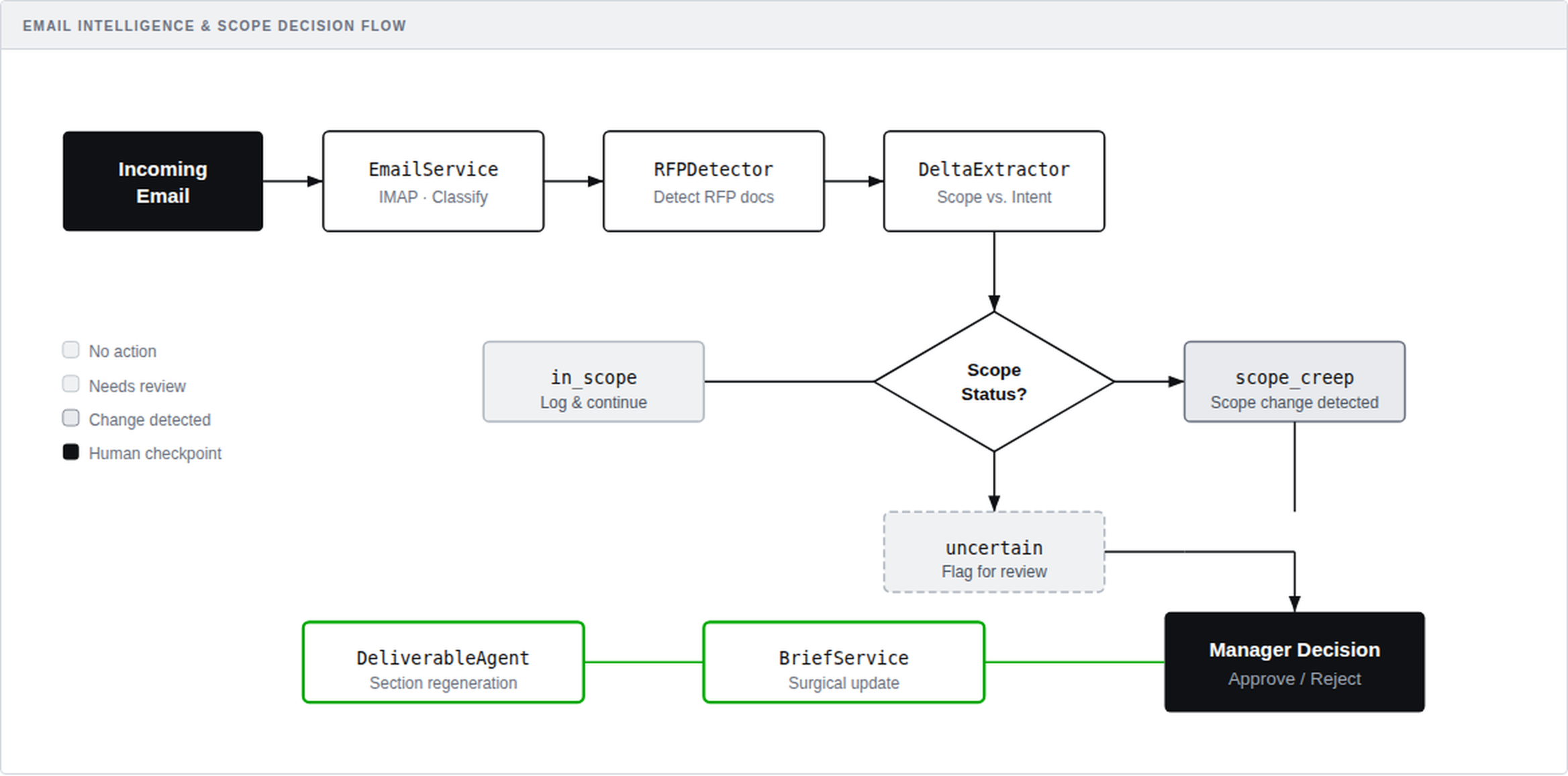
Email Intelligence Pipeline: Incoming emails flow through RFP detection and scope analysis before routing to manager decisions
Most AI integrations ship with static prompt templates. When an unfamiliar task arrives, the system has no answer. This architecture takes a different approach: every task execution dynamically generates its own skill — a custom instruction set built from the project's actual context.
The system uses the PI Coding Agent SDK (pi-mono) — an autonomous agent runtime with a full tool loop — in a two-phase pipeline:
The agent enters read-only mode with file system tools (Read, Grep, Glob). It reads the project brief, RFP documents, communications, existing deliverables, and progress notes from prior sessions. From this exploration, it generates a structured execution plan — effectively a custom skill tailored to this specific task in this specific project context. The user reviews which files the agent read, can reject irrelevant context, and approves or revises the plan before execution begins.
The same agent session unlocks write tools (Write, Edit, Bash) and executes the plan autonomously — creating documents, modifying files, running commands. The agent retains its full exploration context, eliminating information loss between planning and execution. Timeouts prevent runaway execution. Context overflow triggers automatic retries.
A task labelled “prepare financial proposal” gets a completely different generated skill than “competitive landscape analysis” — different source files, different output structure, different execution steps — without either being hardcoded.
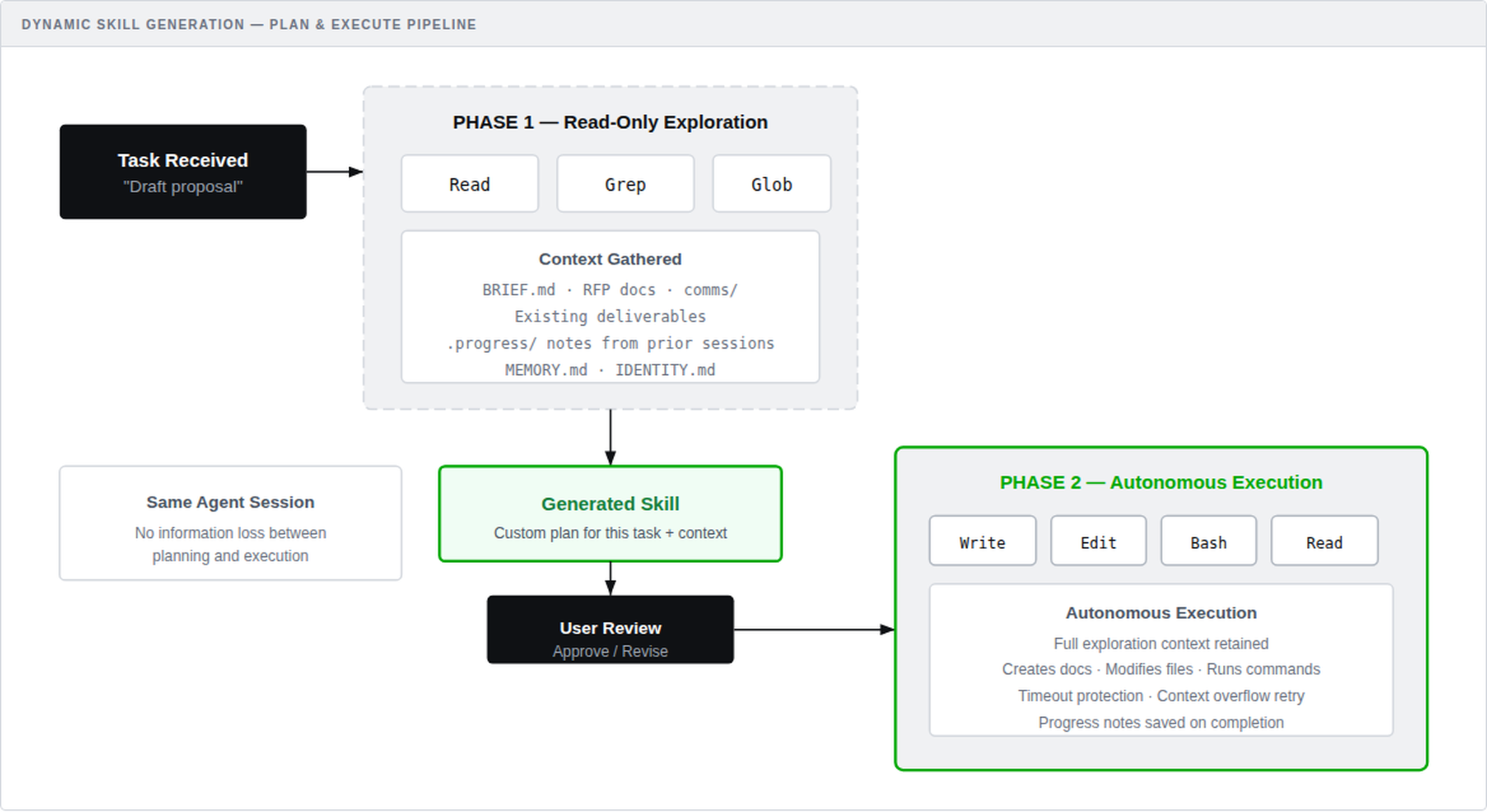
Dynamic Skill Generation: Two-phase pipeline from read-only exploration to autonomous execution with full context
The desktop application runs sqlite-vec for local vector embeddings inside Electron. Once content is indexed, semantic search queries execute locally in milliseconds. Embedding generation uses OpenAI's text-embedding-3-small (1536 dimensions) by default — the embedding provider is replaceable at the configuration level, as the vector store operates on 1536-dimensional vectors regardless of which model generates them. Graceful fallback to FTS5 keyword search runs when offline.
The backend runs Qdrant with PostgreSQL for team-wide vector search. Cross-project queries hit the cloud layer. Single-project work stays local.
A sync layer bridges the two. The desktop holds emails, memory, and chat in local SQLite (better-sqlite3, WAL mode); business data lives in the FastAPI backend and syncs via REST.
Agents without memory are agents that forget. This architecture eliminates cold-start degradation entirely.
All memory files are indexed into SQLite FTS5 for keyword search, with sqlite-vec providing semantic similarity. When an agent resumes a task, readProgressNotes() loads prior context and injects it into the execution prompt. The agent picks up where it left off — no repeated work, no lost context.
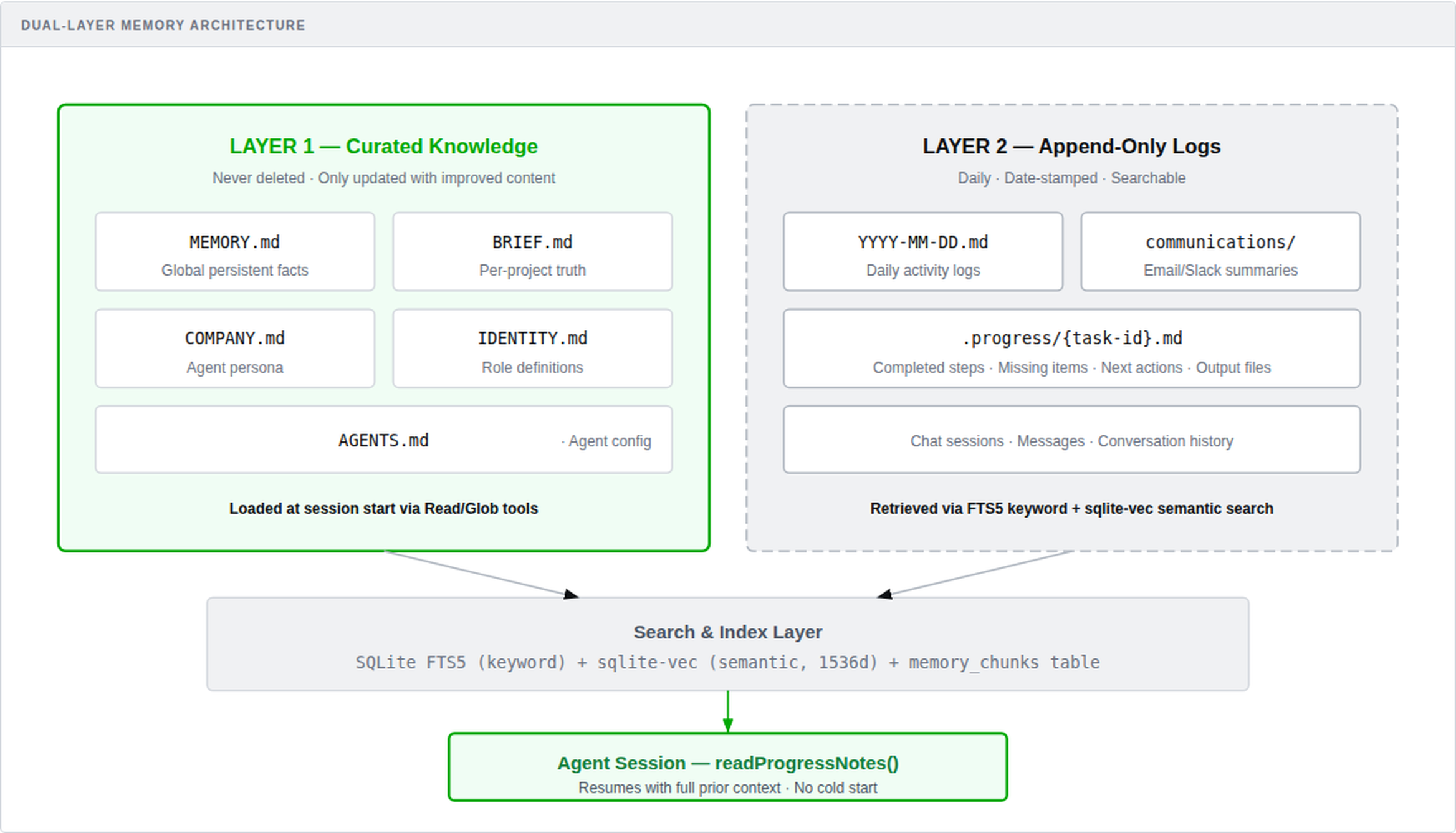
Dual-Layer Memory Architecture: Curated knowledge files and append-only logs feeding into a local search and index layer
Before any architecture decision was made, three constraints were set as non-negotiable. Not as compliance requirements — as the conditions under which a knowledge-intensive organisation would actually trust and run a system like this.
Client communications, engagement documents, institutional knowledge — this is the most sensitive data a knowledge-intensive organisation holds. Any architecture that requires uploading it to a third-party service for processing is a non-starter. The system was designed so that interpretation and intelligence happen locally, on the organisation's own hardware. Data flows up by design, not by default, and only what needs to be shared ever leaves the device.
Token costs are a real operational constraint today and a declining one over time — but the architecture shouldn't assume either. The system was built to minimise API calls structurally: local vector search runs before cloud search, processed inputs are tracked so nothing is classified twice, and keyword matching handles what doesn't need semantic reasoning. The result is a system that gets cheaper as model pricing drops without requiring architectural changes to capture that benefit.
The service architecture — discrete, single-responsibility services for classification, delta extraction, brief management, deliverable generation — was designed so that each service is independently swappable. The system uses specific models today. The design principle is that it doesn't have to. No organisation should be locked into a provider relationship at the infrastructure level of their operations.
Each of the three constraints above maps directly to architectural decisions in the build. The desktop application is not a technology preference — it's the enforcement mechanism.
Emails are parsed locally — never uploaded to a cloud service for processing. Identity files, workspace documents, and progress notes live on the user's machine. Only project metadata and shared knowledge sync to the Nexus. Data flows up by design, not by default.
Processed emails are tracked locally in SQLite — no re-classifying messages the system has already seen. FTS5 keyword search runs free on disk, only falling back to OpenAI embeddings when semantic matching is needed. Local project files enrich every classification prompt without additional retrieval API calls.
The PI agent runs locally with full tool access: Bash, Read, Write, Edit, Glob, Grep — on the user's machine, not in a cloud sandbox. IMAP email access via ImapFlow reads Gmail directly. Document parsing happens in-process: pdf-parse for PDFs, mammoth for DOCX, xlsx for spreadsheets, adm-zip for PPTX.
PKCE OAuth2 flow (RFC 7636) with no client secret in the binary. Context isolation and disabled Node.js integration in the renderer. A controlled contextBridge API surface. Tokens stored in encrypted Electron Store, not browser localStorage.
A scope change affects one section of a deliverable out of twelve — only that section regenerates. The DeliverableSection model tracks each section independently. Unchanged sections stay byte-for-byte identical.
Tasks aren't flat lists. The system generates structured dependency links — depends_on, shares_context, follows — with confidence scoring and reasoning capture. When scope changes, the knowledge graph surfaces impacted tasks automatically.
Extract requirements from RFP → draft per-section → polish assembled document → export as DOCX. DeliverableVersion snapshots track output at each iteration.
Keycloak OIDC with PKCE, role-based access (Partner, Manager, Consultant), and dual role resolution — merging JWT realm roles with database grants.
Projects have distinct modes — proposal and delivery — linked so an engagement transitions naturally from pitch to execution.
This started as a research question, shaped by someone who understood the domain, and produced a working system. The architecture is sound — AI can sit at the interpretation and production layers of a knowledge-intensive operation while humans remain at the decision layer. That question now has a definitive answer, backed by a system that runs.
The engineering patterns hold under real-world complexity: event-driven AI orchestration, local-first intelligence, dynamic skill generation, structured memory. These aren't prototype shortcuts — they're production patterns with real trade-offs and real solutions.
Accuracy improved dramatically when the classifier received each project's full brief and deliverable structure — the same context a human manager would have.
Regenerating entire documents on every change destroys trust. Modify only what the change actually touches.
Dedicated services — RFPDetector, DeltaExtractor, BriefService, DeliverableAgentService — are independently testable and improvable.
Agents that resume with progress notes produce significantly better output than agents starting cold. This is the difference between a system people use and a system people abandon.
R&D rarely ends where it starts. Mapping a domain completely — its workflows, its failure modes, where context gets lost between humans, where structured AI creates an asymmetric advantage — produces more than a working system. It produces a thesis about that domain.
The domain partnership that shaped this research didn't end when the system was built. It accelerated. What began as problem definition has become something more deliberate: a vertical product, co-owned with someone who understands the domain at the level required to build something that actually holds.
We've already started. More when there's something to show.
Monday - Friday: 9:00 AM - 6:00 PM
Saturday - Sunday: Closed


